
Most AI deployments don't fail because the technology is bad. They fail because the deployment strategy doesn't scale. You build something that works beautifully in a controlled test, then watch it buckle under real production load, integration complexity, and unpredictable retry costs. Claude Opus achieved 87% first-pass code acceptance across more than 12,000 API calls, proving that quality choices at the model level directly shape your total cost of ownership. This guide gives you a stepwise, evidence-backed framework to deploy AI agents at scale without sacrificing quality, budget, or operational control.
Table of Contents
- Understand the challenges of scaling AI deployments
- Pre-deployment checklist: What you need before scaling AI
- Step-by-step: Deploying scalable AI agents across your platforms
- Monitoring, optimization, and troubleshooting at scale
- Accelerate your AI deployment with expert AI agent solutions
- Frequently asked questions
Key Takeaways
| Point | Details |
|---|---|
| Plan for scalability | Success with AI automation depends on robust infrastructure, skilled teams, and process readiness. |
| Prioritize quality and cost | Choose AI solutions with proven high pass rates and lower retry costs for enterprise automation. |
| Leverage enterprise MLOps | Platforms like Kubeflow and Kubernetes are vital for efficient, secure, and agile AI scaling. |
| Monitor and iterate | Tracking key metrics and troubleshooting continuously keeps deployments efficient and reliable. |
Understand the challenges of scaling AI deployments
Scaling AI is not just a bigger version of a pilot project. The moment you move from a proof of concept to a production environment serving real business workflows, you encounter a completely different class of problems. Integration complexity multiplies fast. Every new platform connection introduces potential failure points, authentication layers, and data format mismatches.
Cost unpredictability is another major trap. Many teams underestimate how retry loops, failed completions, and low-quality outputs compound into serious budget overruns. A model that looks cheap per call can become expensive when it requires two or three attempts to produce usable output. Claude Opus's 87% first-pass rate versus GPT's 79% illustrates exactly this: a higher sticker price per call can still be net cost-competitive when retries drop significantly.
Here are the most common pain points business leaders encounter when scaling AI:
- Integration complexity: Connecting agents to legacy systems, APIs, and cloud services without breaking existing workflows
- Platform scalability: Choosing infrastructure that handles variable load without manual intervention
- Unpredictable costs: Retry loops, rework cycles, and low-quality outputs that inflate operational spend
- Quality leakage: Outputs that degrade as volume increases, especially without proper monitoring
- Organizational resistance: Teams that aren't trained or aligned to work alongside autonomous agents
"The real cost of a poor LLM choice isn't the price per token. It's the rework, the retries, and the engineering hours spent patching outputs that should have been right the first time."
Understanding AI workforce management principles early helps you frame these challenges not as technical bugs but as organizational design problems. That shift in perspective changes how you plan, staff, and budget your deployment.
Pre-deployment checklist: What you need before scaling AI
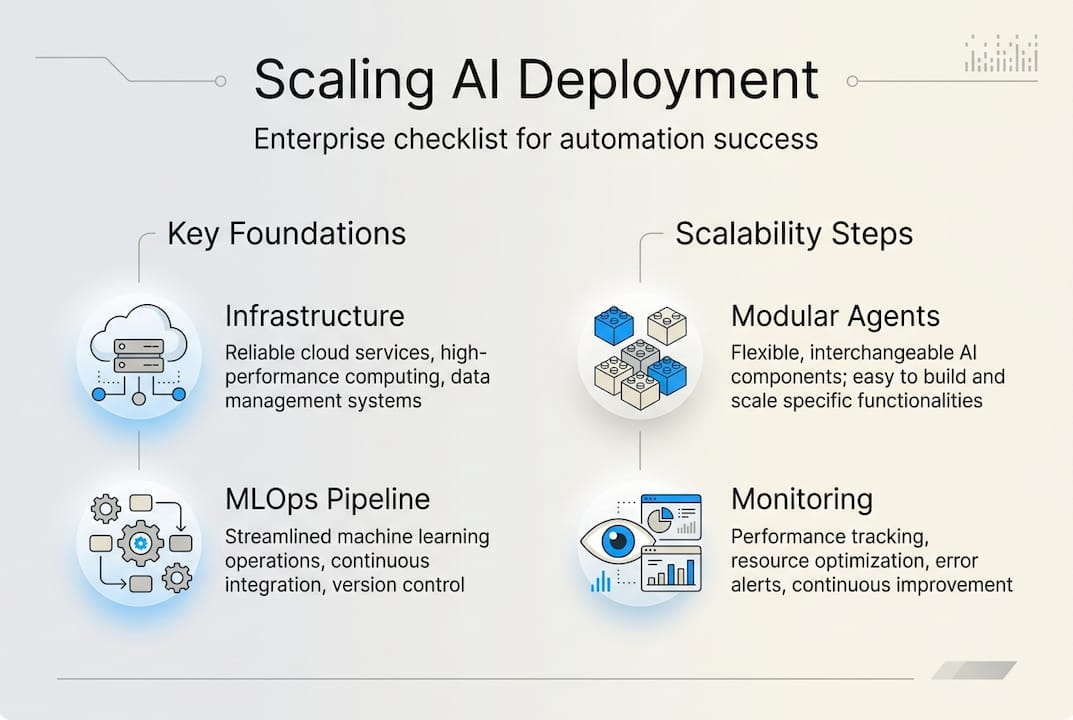
Rushing into deployment without the right foundation is the fastest way to create expensive technical debt. Before you scale a single agent, you need to verify readiness across five dimensions: infrastructure, team capability, data access, compliance, and platform selection.
| Readiness area | What to verify | Why it matters |
|---|---|---|
| Infrastructure | Cloud scalability, GPU availability, container orchestration | Handles variable load without manual scaling |
| MLOps platform | Kubernetes, Kubeflow, or KServe configured | Enables multi-tenancy and GitOps workflows |
| Team capability | AI literacy, prompt engineering, monitoring skills | Reduces dependency on external consultants |
| Data access | Clean, labeled, compliant data pipelines | Prevents model drift and output degradation |
| Compliance | GDPR, SOC 2, data residency requirements | Avoids regulatory exposure at scale |
Kubernetes-powered MLOps platforms like Kubeflow and KServe provide the essential enterprise features you need: multi-tenancy so different teams or clients share infrastructure safely, GPU optimization for compute-heavy workloads, GitOps workflows for version-controlled deployments, and support for model distillation at the edge. Without this layer, you're essentially managing AI deployments manually, which doesn't scale.
Your pre-deployment checklist should include:
- Confirm executive sponsorship and a clear business case with measurable KPIs
- Audit existing data pipelines for quality, completeness, and compliance
- Select and configure your cloud services for AI deployment before writing a single agent config
- Establish a model governance policy covering versioning, rollback procedures, and access controls
- Run a load test on your infrastructure using simulated agent traffic before go-live
Pro Tip: Don't skip the load test. A deployment that handles 100 concurrent agent tasks in staging may fail at 500 in production if your container orchestration isn't configured for horizontal pod autoscaling. Test at 2x your expected peak load.
Step-by-step: Deploying scalable AI agents across your platforms
With your foundation in place, here is the deployment sequence that consistently produces reliable, scalable results for enterprise teams.
Step 1: Choose your LLM and automation platform. Model selection is a strategic decision, not a commodity choice. Claude Opus's production stats show that a higher first-pass acceptance rate directly reduces retry loops and total operational cost. Evaluate models on quality metrics, not just price per token.
Step 2: Design a modular agent architecture. Each agent should have a single, well-defined responsibility. Modular design means you can swap, upgrade, or scale individual agents without rebuilding your entire workflow. This is the foundation of interoperability across platforms.
Step 3: Configure your MLOps pipeline. Kubernetes-based MLOps gives you the multi-tenant infrastructure and GPU resource optimization needed for enterprise-scale operations. Set up CI/CD pipelines for agent updates so changes deploy automatically after passing quality gates.

Step 4: Integrate agents across platforms. Connect agents to your target platforms using standardized APIs. Follow the agent deployment steps that cover authentication, permission scoping, and error handling for each integration point.
Step 5: Run a staged rollout. Deploy to a small user segment first. Measure first-pass success rates, latency, and error frequency before expanding. This is where most teams catch integration bugs before they become production incidents.
Step 6: Scale and automate monitoring. Once stable, automate your scaling rules and set up alerting for quality degradation. Review AI workforce management tips to structure your human oversight layer effectively.
Here's how single-agent and multi-agent frameworks compare for business operations:
| Factor | Single-agent framework | Multi-agent framework |
|---|---|---|
| Setup complexity | Low | Medium to high |
| Task specialization | Limited | High |
| Fault tolerance | Low (single point of failure) | High (redundant agents) |
| Scalability | Moderate | Excellent |
| Best for | Simple, linear workflows | Complex, parallel business processes |
For most enterprise use cases, multi-agent teams outperform single-agent setups because they allow parallel task execution, specialization, and built-in redundancy. A customer support operation, for example, benefits from separate agents handling triage, escalation, and resolution rather than one agent trying to do everything.
Pro Tip: When building multi-agent systems, assign each agent a named role with explicit permissions. Agents that can do everything tend to do nothing well. Tight role definitions improve output quality and make troubleshooting dramatically faster.
Monitoring, optimization, and troubleshooting at scale
Deployment is not the finish line. The teams that extract the most value from AI automation are the ones that treat monitoring as a core operational function, not an afterthought. Quality and cost are directly linked: production retry rates and first-pass success metrics are the clearest early indicators of whether your deployment is healthy or quietly burning budget.
Track these key metrics from day one:
- First-pass success rate: The percentage of agent outputs accepted without rework or retry. Anything below 80% signals a model quality or prompt engineering problem.
- Retry frequency and cost: How often agents loop back to regenerate output, and what that costs per workflow.
- Operational latency: End-to-end time from trigger to completed task. Latency spikes often indicate infrastructure bottlenecks, not model issues.
- Integration error rate: Failed API calls, authentication timeouts, and data format mismatches across connected platforms.
- Model drift indicators: Gradual degradation in output quality over time, often caused by data distribution shifts.
Spotting bottlenecks early requires structured logging. Every agent action should emit a structured log entry with a timestamp, task ID, model used, output status, and latency. This gives you the data to run root cause analysis when something goes wrong.
For continuous improvement, schedule monthly model performance reviews. Compare current first-pass rates against your baseline. If quality is slipping, investigate whether your prompts need updating, your training data has drifted, or your model version needs upgrading. Connecting your agents to domain expert operators can also inject specialized knowledge that keeps outputs accurate as your use cases evolve.
Pro Tip: Set a cost-per-workflow budget alert, not just a total spend alert. A single runaway agent workflow can consume disproportionate resources before a monthly budget cap triggers. Granular alerting catches problems in hours, not weeks.
Common troubleshooting scenarios at scale include integration bugs from API version mismatches, data mismatch errors when upstream schemas change without notice, and scaling errors when container resource limits aren't tuned for peak load. Document each incident with a root cause and resolution so your team builds institutional knowledge over time.
Accelerate your AI deployment with expert AI agent solutions
You now have the full deployment framework: from understanding scaling challenges to monitoring production performance. The next step is putting it into practice with tools built specifically for enterprise-grade AI automation.
AgentsBooks gives you a purpose-built platform to create, configure, and deploy autonomous AI agents across every major platform your business relies on. Whether you need domain expert operators for specialized workflows or want to orchestrate AI multi-agent teams for complex parallel operations, the platform handles the infrastructure complexity so your team focuses on outcomes. With configurable LLM brains, trigger-based automation, and a developer-friendly REST API, scaling from one agent to hundreds is a configuration decision, not an engineering project. Visit AI Agents Factory to explore how AgentsBooks can accelerate your deployment timeline and reduce operational risk.
Frequently asked questions
What are the essential factors for scalable AI deployment?
Select robust automation platforms, ensure your infrastructure supports horizontal scaling, and prioritize high-quality models to minimize retries. Claude Opus's 87% first-pass acceptance rate demonstrates that model quality is a direct cost and scalability lever.
Should I use Kubernetes or MLOps for enterprise-scale AI deployment?
Yes, Kubeflow and KServe provide the multi-tenancy, GPU optimization, and GitOps workflows that enterprise AI deployments require for sustainable operations. They are not optional at scale.
How do I ensure quality control in large-scale AI deployments?
Monitor first-pass success rates and retry frequency as your primary quality signals, then retrain or reprompt when metrics degrade. 87% first-pass acceptance in production shows what a well-tuned deployment looks like.
What's the best way to handle integration across multiple platforms?
Adopt modular agent architectures with standardized API connections and enforce MLOps workflows that version-control every integration change. This prevents cascading failures when one platform updates its schema or authentication requirements.